记录scrapy的一些笔记
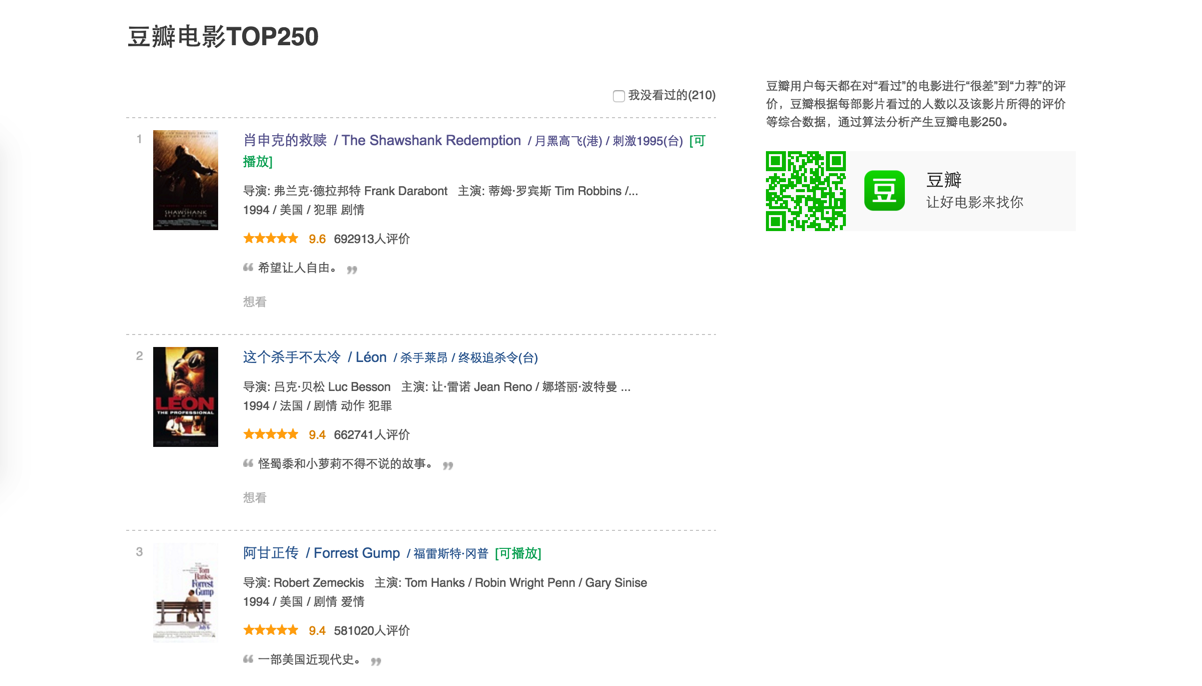
scrapy是python开发的一个快速web爬虫抓取框架,用于抓取web站点并从页面中提取结构化的数据。scrapy用途广泛,可以用于数据挖掘,监测和自动化测试。下面我们通过抓取豆瓣电影top排行榜来熟悉scrapy。
scrapy官方介绍是:
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
首先呢,我们使用scrapy创建一个项目:
scrapy startproject topmovie
然后scrapy会创建好我们的项目基本结构。
scrapy文件结构一般如下:
scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
items.py定义需要抓取并需要后期处理的数据。来看我们的items.py文件:
from scrapy import Item, Field
class TopmovieItem(Item):
title = Field()
movieInfo = Field()
star = Field()
quote = Field()
Item就是我们保存爬取到的数据的容器。
title类似字典中的“键”,爬到的数据类似字典中的“值”。
官方手册:
Item objects are simple containers used to collect the scraped data. They provide a dictionary-licke API with a convenient syntax for declaring their available fields.
settings.py文件配置scrapy,从而修改user-agent,设定爬取时间间隔,设置代理,配置各种中间件等等。
The Scrapy settings allows you to customize the behaviour of all Scrapy components, including the core, extensions, pipelines and spiders themselves.
例如:
BOT_NAME = 'topmovie'
SPIDER_MODULES = ['topmovie.spiders']
NEWSPIDER_MODULE = 'topmovie.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.86 Safari/537.36'
# 建一个csv文件并将爬取的信息保存到这个文件下面
FEED_URI = '/Users/puronglong/Desktop/result.csv'
FEED_FORMAT = 'CSV'
pipeline.py用于存放执行后期数据处理的功能,从而使得数据的爬取和处理分开。
After an item has been scraped by a spider, it is sent to the Item Pipeline which process it through several components that are executed sequentially.
我们这里并没有进行什么操作所以使用默认的:
class TopmoviePipeline(object):
def process_item(self, item, spider):
return item
了解了文件结构之后然后在spiders目录下编辑我们的爬虫代码:
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.http import Request
from scrapy.selector import Selector
from topmovie.items import TopmovieItem
class Douban(CrawlSpider):
#这个name的值定义的就是scrapy crawl name里面的name的值
name = 'topmovie'
redis_key = 'topmovie:start_urls'
#爬虫默认入口地址
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self, response):
item = TopmovieItem()
selector = Selector(response)
#每一个电影的相关信息都在一个class为info的div下面
Movies = selector.xpath('//div[@class="info"]')
for eachMovie in Movies:
title = eachMovie.xpath('div[@class="hd"]/a/span/text()').extract()
fullTitle = ''
for each in title:
fullTitle += each
MovieInfo = eachMovie.xpath('div[@class="bd"]/p/text()').extract()
star = eachMovie.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMovie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,进行判断,quote是电影中的一句名言
if quote:
quote = quote[0]
else:
quote = ''
#把获取到的值赋给我们的item
item['title'] = fullTitle
item['movieInfo'] = MovieInfo[0] + '\n' + MovieInfo[1]
item['star'] = star
item['quote'] = quote
#使用yield进行迭代
yield item
#获取到下一页的链接
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextLink:
nextLink = nextLink[0]
print nextLink
#获取新的链接,再次调用此函数
yield Request(self.url + nextLink, callback=self.parse)
yield是一个类似return的关键字,只是这个函数返回的是个生成器。
看看爬取的结果吧:
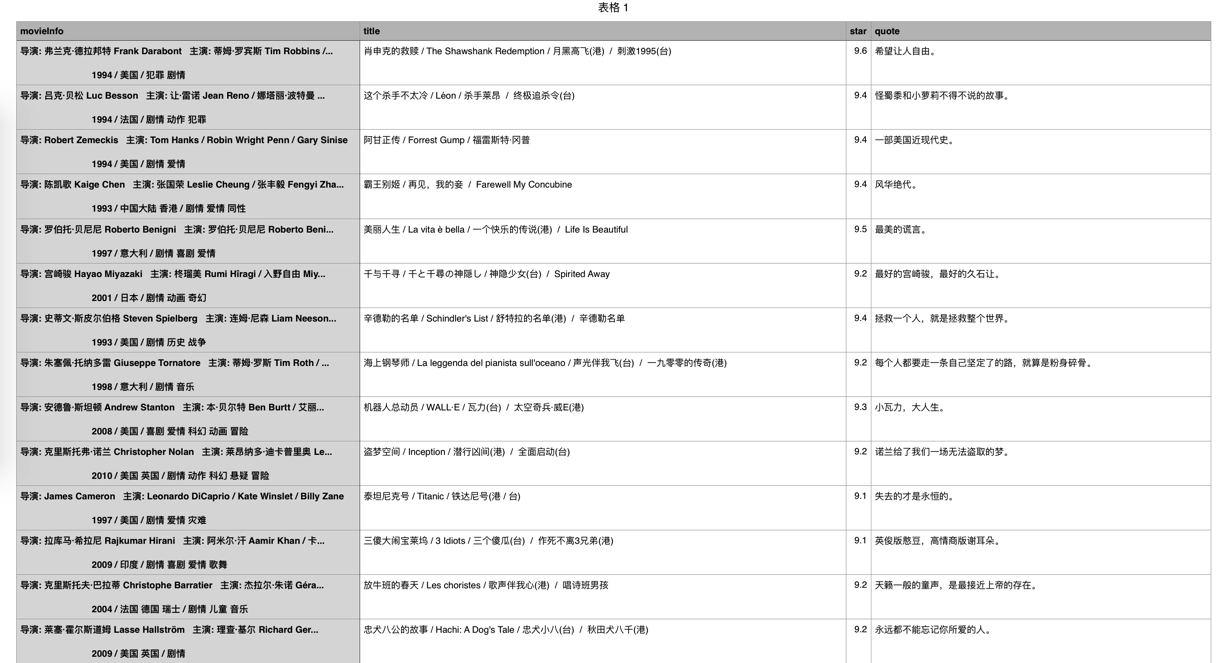
取下来了,棒棒哒~


