xpath笔记
当我们使用爬虫对网页进行爬取的时候,重要的一步就是对我们爬取的网页中所需要的数据进行提取,那么问题来了,怎么匹配出那些我们需要的数据呢?这就要提到正则表达式了,我们可以使用正则来搜索我们需要的信息,但是正则功能强大,弊端在于容易出错且繁琐复杂,而xpath本就是为解析html和xml而做的,使用它来匹配就非常方便了。让我们一起来学学吧。
xpath是一门在xml文档中查找信息的语言。xpath可以用来在xml文档中对元素和属性进行遍历。
选取节点:
xpath使用路径表达式来选取xml文档中的节点或节点集。节点是通过沿着路径或者步来选取的。
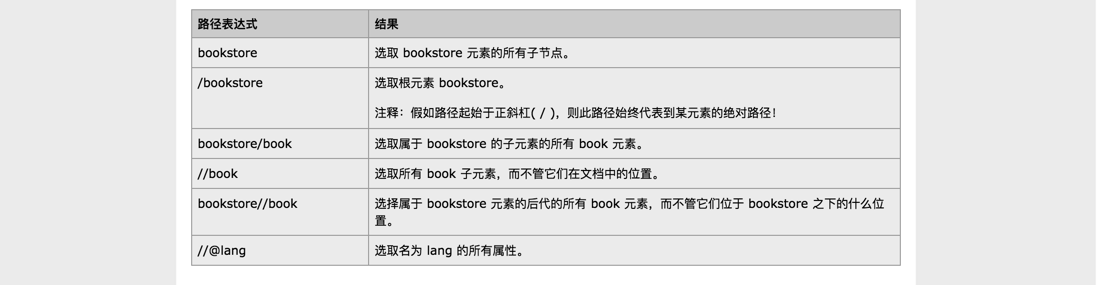
下面列出了一些常用的路径表达式:
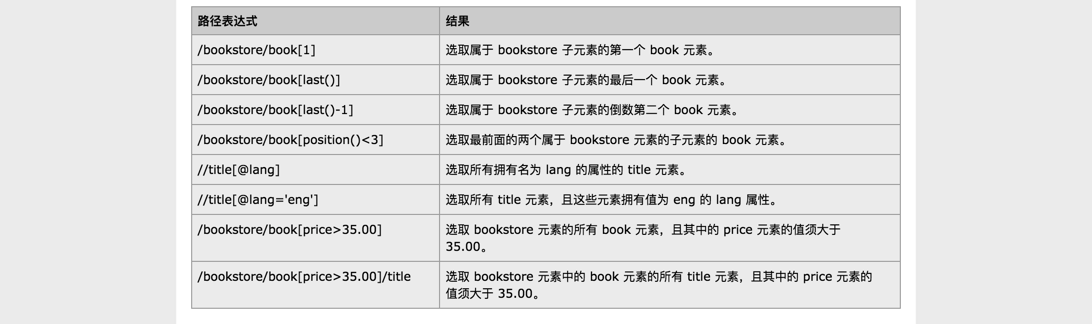
谓语:
谓语用来查找某个特定的节点或包含某个指定的值的节点。
谓语被嵌在方括号中。
选取未知节点:
xpath通配符可用来选取未知的xml元素。

选取若干路径:
| 通过在路径表达式中使用“ | ”运算符,您可以选取若干个路径。 |

位置路径表达式
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:
/step/step/...
相对位置路径:
step/step/...
下面列出了可用在 XPath 表达式中的运算符:
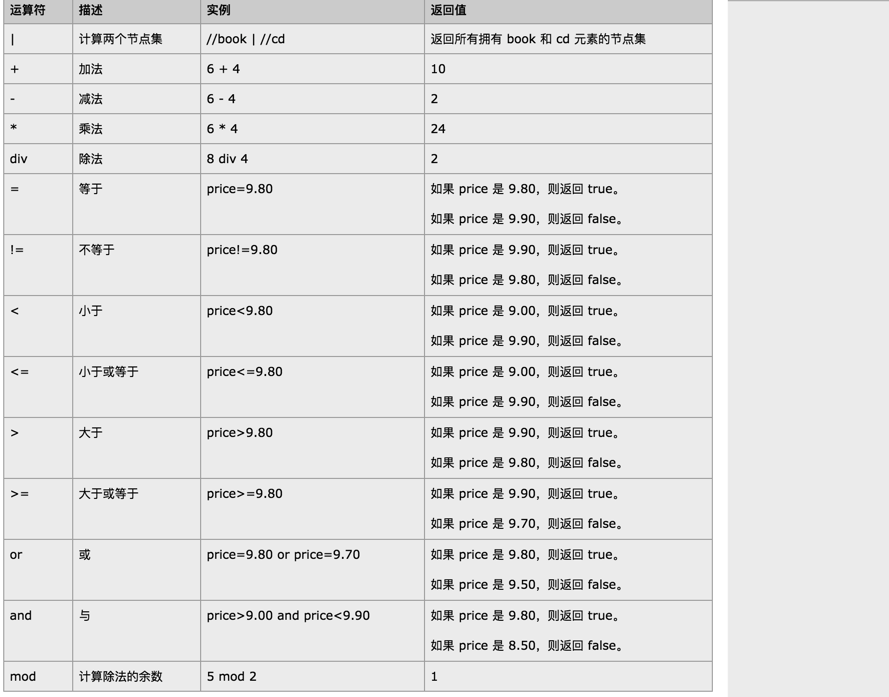
选取价格高于 35 的所有 title 节点:
/bookstore/book[price>35]/title